GO enrichment¶
A script for running GO term enrichment and producing plots from it.
- GOEnrichment.go_enrichment(go_genes, title_tag='', out_tag='', max_terms='all', organism='hsapiens', background=None, numerate=False, godf_only=False, wanted_sources=['GO:MF', 'GO:BP', 'KEGG', 'REAC', 'HP', 'WP'], keywords={}, cmap='plasma', fig_width=None, fig_height=None, legend_out=None, rotation=45, font_s=16, custom_dfs=None, formats=['pdf'])¶
Requires a dictionary with sets of genes. Will run GO enrichment for each of the sets. One plot will be written for each GO source. For only one gene set uses the x-axis for indicating the FDR, multiple sets will be separated on the x-axis and the FDR value shown as colour. Note, root terms of the databases are manually filtered out (e.g., HP root), but some might be missed. Uses the Python package of g:Profiler:
- Parameters:
go_genes – {class: [class genes] for class in classes}, or as sets. Safest identifiers are Ensembl IDs.
max_terms – Allow a maximum of max_terms per dict key. Use ‘all’ to get all.
organism – ‘hsapiens’ for human, ‘mmusculus’ for mouse. Check the g:Profiler page for all options.
background – Same as go_genes but holding the set of background genes for each entry in go_genes. The keys of the two dictionaries will be matched. Leave empty to not use any background.
numerate – Show the size of the gene sets in parentheses on the x-axis.
godf_only – Skip the plotting step and only return the df.
wanted_sources – Which databases to plot.
keywords – A dictionary of {source: list of keywords}, e.g. {GO:BP: [‘vascular’, ‘angio’]}, to limit the plot to terms containing any of the listed strings. Capitalization doesn’t matter, string comparison is done on the lowered strings.
custom_dfs – Very specific use case. {gene set: {go_source: DF}}; In case an external df was used or a g:Profiler was customized, to just use the plotting part. Must have the same format as the g:Profiler DFs.
- Returns:
Returns a dict of {key df} with a df for each gene set as provided by the gprofiler package, which includes which genes matched to which terms.
import GOEnrichment
out_dir = 'docs/gallery/' # Replace with wherever you want to store it.
# We're using a handful of genes from studies finding genes related to Coronary Artery Disease (CAD).
# 10.1161/CIRCRESAHA.117.312086 and 10.1038/s41586-024-07022-x
gene_sets = {"CAD-van der Harst": set(open('ExampleData/VanderHarst2018.txt').read().strip().split('\n')),
'CAD-Schnitzler ': set(open('ExampleData/Schnitzler2024.txt').read().strip().split('\n'))}
# First let's run only one of them.
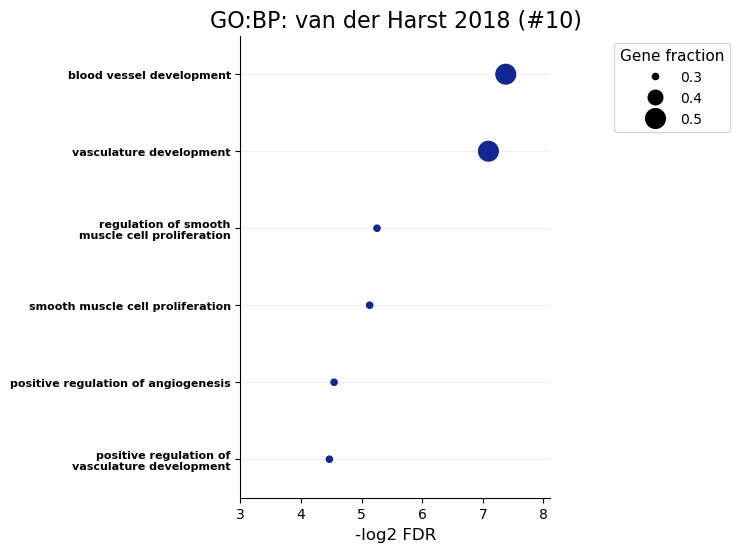
go_dict = GOEnrichment.go_enrichment({"CAD-van der Harst": gene_sets['CAD-van der Harst']}, title_tag='van der Harst 2018',
out_tag=out_dir+'VanDerHarst', max_terms='all', organism='hsapiens',
numerate=True, wanted_sources=['GO:BP'], rotation=45, font_s=16, formats='png')
print(go_dict['CAD-van der Harst'].head(n=3)) # The print is a bit ugly with so many columsn.
source native name p_value \
0 GO:MF GO:0030169 low-density lipoprotein particle binding 0.004557
1 GO:BP GO:0001568 blood vessel development 0.005963
2 GO:BP GO:0001944 vasculature development 0.007327
significant description term_size \
0 True "Binding to a low-density lipoprotein particle... 16
1 True "The process whose specific outcome is the pro... 721
2 True "The process whose specific outcome is the pro... 752
query_size intersection_size effective_domain_size precision recall \
0 10 2 20212 0.200000 0.125000
1 9 5 21031 0.555556 0.006935
2 9 5 21031 0.555556 0.006649
query parents \
0 query_1 [GO:0071813]
1 query_1 [GO:0001944, GO:0048856]
2 query_1 [GO:0048731, GO:0072359]
intersections \
0 [ENSG00000140945, ENSG00000169174]
1 [ENSG00000140945, ENSG00000122691, ENSG0000016...
2 [ENSG00000140945, ENSG00000122691, ENSG0000016...
evidences Gene fraction
0 [[IDA], [ISS, IEA]] 0.2
1 [[IDA, IBA], [NAS], [IDA, ISS, IEA], [TAS, IEA... 0.5
2 [[IDA, IBA], [NAS], [IDA, ISS, IEA], [TAS, IEA... 0.5
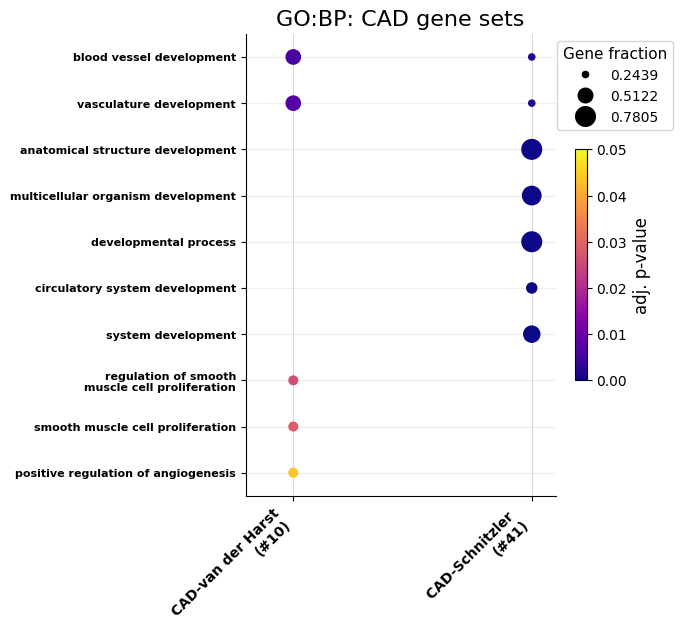
# Next, we can see how both gene sets look like. The second gene set has a huge amount of terms enriched, so we limit
# it to the top 5 from each gene set.
go_dict = GOEnrichment.go_enrichment(gene_sets, title_tag='CAD gene sets',
out_tag=out_dir+'BothSets', max_terms=5, organism='hsapiens',
numerate=True, wanted_sources=['GO:BP'], rotation=45, font_s=16, formats='png')
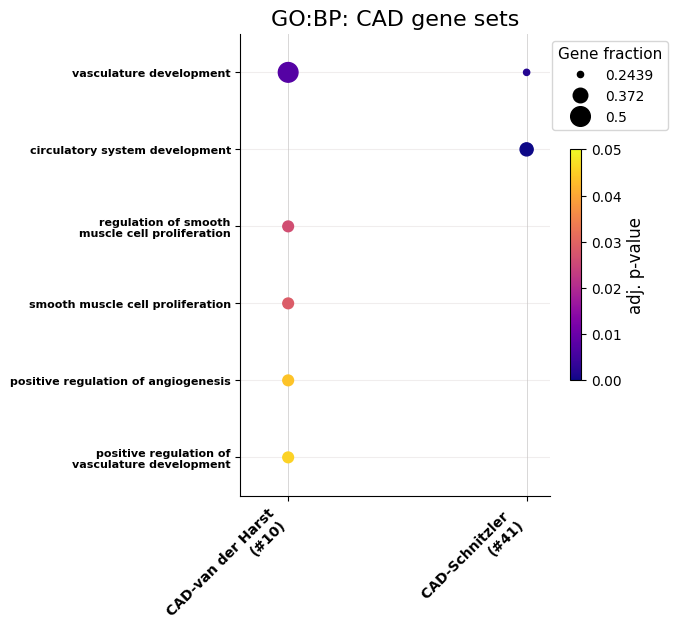
# Instead of limiting the terms to the most enriched ones, an alternative is to filter for specific keywords.
go_dict = GOEnrichment.go_enrichment(gene_sets, title_tag='CAD gene sets', keywords={"GO:BP": ['angio', 'vasc', 'circ', 'muscle']},
out_tag=out_dir+'BothSetsFiltered', max_terms='all', organism='hsapiens',
numerate=True, wanted_sources=['GO:BP'], rotation=45, font_s=16, formats='png')